
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 버퍼오버플로우
- 스택
- 카이사르
- Protostar
- KOISTUDY
- WEB
- general skills
- 리버싱
- 리눅스
- 정답
- grep
- #picoCTF2018
- CTF
- picoCTF
- Aleph One
- writeup
- Smashing The Stack For Fun And Profit
- write up
- cryptography
- dreamhack
- 해킹 공부
- Hxd
- picoCTF2018
- 해설
- reversing
- 시스템
- 번역
- forensics
- #hacking
- 시스템해킹
Archives
- Today
- Total
Security || AI
2. 악성코드 PE 추출 with pickle, pefile 본문
1. Dos Header 추출
def Dos_Header(pe):
#print(file)
features = []
temp = pe.DOS_HEADER
features.append(temp.e_cblp)
features.append(temp.e_cp)
features.append(temp.e_crlc)
features.append(temp.e_cparhdr)
features.append(temp.e_minalloc)
features.append(temp.e_maxalloc)
features.append(temp.e_ss)
features.append(temp.e_sp)
features.append(temp.e_csum)
features.append(temp.e_ip)
features.append(temp.e_cs)
features.append(temp.e_lfarlc)
features.append(temp.e_oemid)
features.append(temp.e_oeminfo)
features.append(temp.e_lfanew)2. File Header 추출
def File_Header(pe):
features = []
temp = pe.FILE_HEADER
features.append(temp.Machine)
features.append(temp.NumberOfSections)
features.append(temp.PointerToSymbolTable)
features.append(temp.NumberOfSymbols)
features.append(temp.SizeOfOptionalHeader)
features.append(temp.Characteristics)
if temp.NumberOfSections == len(pe.sections):
features.append(1)
else:
features.append(0)
return features3. Optional Header 추출
def Optional_Header(pe):
features = []
temp = pe.OPTIONAL_HEADER
features.append(temp.Magic)
features.append(temp.MajorLinkerVersion)
features.append(temp.MinorLinkerVersion)
features.append(temp.SizeOfCode)
features.append(temp.SizeOfInitializedData)
features.append(temp.SizeOfUninitializedData)
features.append(temp.AddressOfEntryPoint)
features.append(temp.BaseOfCode)
features.append(temp.ImageBase)
features.append(temp.SectionAlignment)
features.append(temp.FileAlignment)
features.append(temp.MajorOperatingSystemVersion)
features.append(temp.MinorOperatingSystemVersion)
features.append(temp.MajorImageVersion)
features.append(temp.MinorImageVersion)
features.append(temp.MajorSubsystemVersion)
features.append(temp.MinorSubsystemVersion)
features.append(temp.Reserved1)
features.append(temp.SizeOfImage)
features.append(temp.SizeOfHeaders)
features.append(temp.CheckSum)
features.append(temp.Subsystem)
features.append(temp.DllCharacteristics)
features.append(temp.SizeOfStackReserve)
features.append(temp.SizeOfStackCommit)
features.append(temp.SizeOfHeapReserve)
features.append(temp.SizeOfHeapCommit)
features.append(temp.LoaderFlags)
features.append(temp.NumberOfRvaAndSizes)
return features4. Data Directory 추출
def Data_Directory(pe):
features = []
temp = pe.OPTIONAL_HEADER.DATA_DIRECTORY
count = 0
for i in temp:
features.append(i.VirtualAddress)
features.append(i.Size)
count += 1
#print(len(features))
for m in range(count, 16):
features.append(0)
features.append(0)
#print(len(features))
return features5. Section 영역 추출
ef Sections(pe):
text = []
data = []
rsrc = []
rdata = []
reloc = []
sections = pe.sections
other_section_count = 0
for f in sections:
name = str(f.Name, encoding="utf8").strip('\x00')
if name == '.text' or name == '.data' or name == '.rsrc' \
or name == '.rdata' or name == '.reloc':
list = []
list.append(f.Misc_VirtualSize)
list.append(f.VirtualAddress)
list.append(f.SizeOfRawData)
list.append(f.PointerToRawData)
list.append(f.PointerToRelocations)
list.append(f.PointerToLinenumbers)
list.append(f.NumberOfRelocations)
list.append(f.NumberOfLinenumbers)
list.append(f.Characteristics)
if name == '.text':
text = list
elif name == '.data':
data = list
elif name == '.rsrc':
rsrc = list
elif name == '.rdata':
rdata = list
elif name == '.reloc':
reloc = list
else:
other_section_count += 1
if len(text) == 0:
for i in range(9):
text.append(0)
if len(data) == 0:
for i in range(9):
data.append(0)
if len(rsrc) == 0:
for i in range(9):
rsrc.append(0)
if len(rdata) == 0:
for i in range(9):
rdata.append(0)
if len(reloc) == 0:
for i in range(9):
reloc.append(0)
text.extend(data)
text.extend(rsrc)
text.extend(rdata)
text.extend(reloc)
#print(len(text))
text.append(other_section_count)
return text6. Resources 영역 추출
def Resources(pe):
features = []
types = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 17, 19, 20, 21, 22, 23, 24]
try:
temp = pe.DIRECTORY_ENTRY_RESOURCE
except:
features.append(0)
for _ in types:
features.append(0)
return features
features.append(temp.struct.NumberOfNamedEntries + temp.struct.NumberOfIdEntries)
for i in types:
exist = False
for x in temp.entries:
if x.id == i:
features.append(x.directory.struct.NumberOfNamedEntries + x.directory.struct.NumberOfIdEntries)
exist = True
break
if not exist:
features.append(0)
return features7. DLL, API 영역 추출
def Imported_DLL_and_API(pe):
dlls = []
apis = []
try:
temp = pe.DIRECTORY_ENTRY_IMPORT
#print(type(temp), temp)
except:
result = []
for i in range(53):
result.append(0)
return result
for i in temp:
if i.dll: dlls.append(str(i.dll.upper(), encoding="utf8"))
for j in i.imports:
if j.name: apis.append(str(j.name.upper(), encoding="utf8"))
dll = []
api = []
for key in dll_dict.keys():
exist = False
for i in dlls:
if i == key:
#print(key)
dll.append(1)
exist = True
break
if not exist:
dll.append(0)
for key in api_dict.keys():
exist = False
for i in apis:
if i == key:
api.append(1)
exist = True
break
if not exist:
api.append(0)
result = dll
result.extend(api)
result.append(len(dlls))
result.append(len(apis))
return result
결과
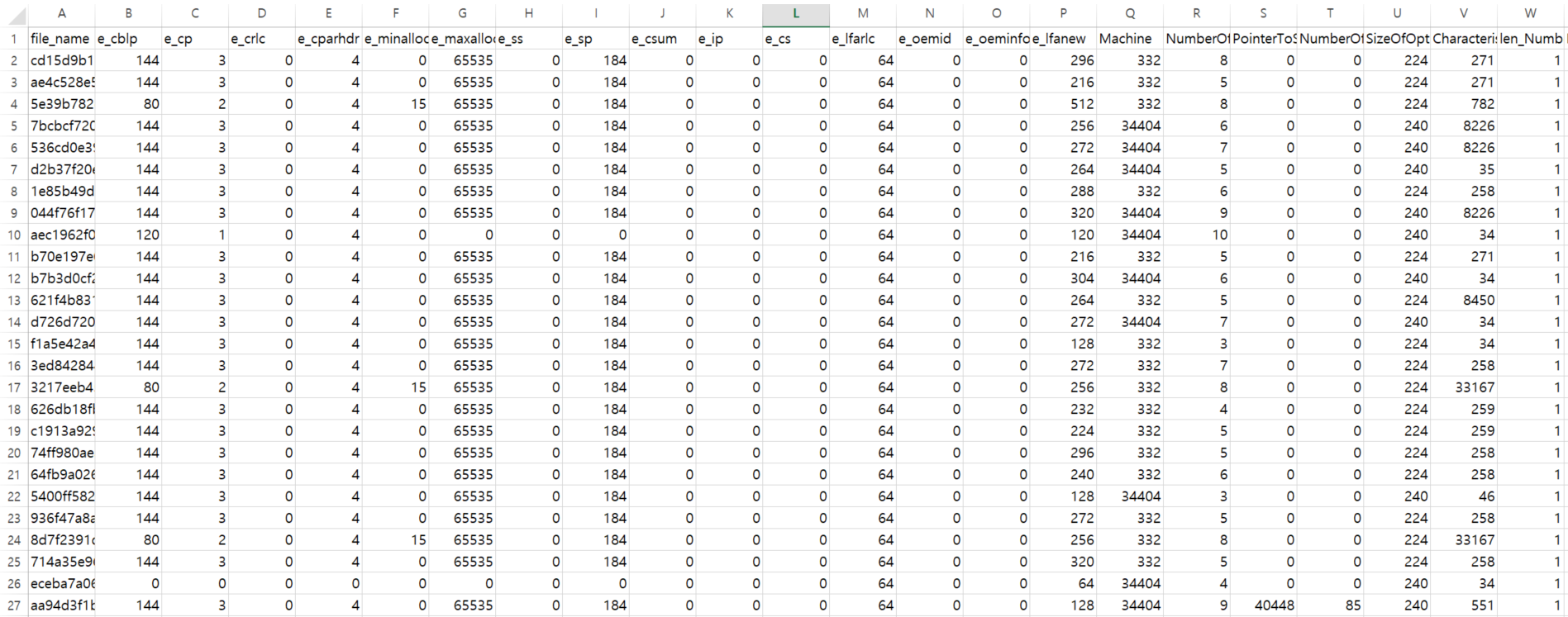
하나의 파일당 604개의 feature를 추출하였다.
총 1만개의 악성코드 feature를 추출하는데 걸린 시간은 1740초(29분)만큼 소요됐다.

반응형
'프로젝트 > RL_Malware' 카테고리의 다른 글
| 3. 추출한 악성코드 pe 헤더 추가하기 (0) | 2021.02.15 |
|---|---|
| 1. 데이터 분류하기 with Pandas, os (0) | 2021.02.14 |
'프로젝트/RL_Malware' Related Articles
more

