
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Hxd
- 리버싱
- picoCTF2018
- picoCTF
- CTF
- cryptography
- 리눅스
- 스택
- WEB
- Smashing The Stack For Fun And Profit
- 시스템해킹
- 버퍼오버플로우
- Aleph One
- grep
- 해킹 공부
- #picoCTF2018
- general skills
- KOISTUDY
- 시스템
- 카이사르
- Protostar
- dreamhack
- forensics
- write up
- #hacking
- 정답
- reversing
- writeup
- 해설
- 번역
- Today
- Total
Security || AI
[강화학습] A3C의 개념, 장점, 구조 본문
A3C란?
A3C 알고리즘은 비동기적 어드밴티지 액터크리틱(Asynchronous Advantage Actor-Critic)으로, 2016년 구글 딥마인드가 발표한 알고리즘이다.
학습 데이터간의 상관관계를 꺠기 위해 DQN에서와 같이 리플레이 메모리를 사용하는 것이 아니라, 샘플을 수집하는 여러 개의 ACTOR-LEARNER라는 에이전트를 사용하는 Actor-Critic 방법이다.
장점
-
A3C 알고리즘은 강화학습 문제에서 더 좋은 보상을 달성 가능하다.
-
기존 방식과 동일한 액션 공간에서 연속적으로나 별도로 동작하는 것이 가능하다.
-
학습 속도가 빠르다.
-
DGN보다 시간이 단축되고, 학습 성능이 뛰어나다.
구조
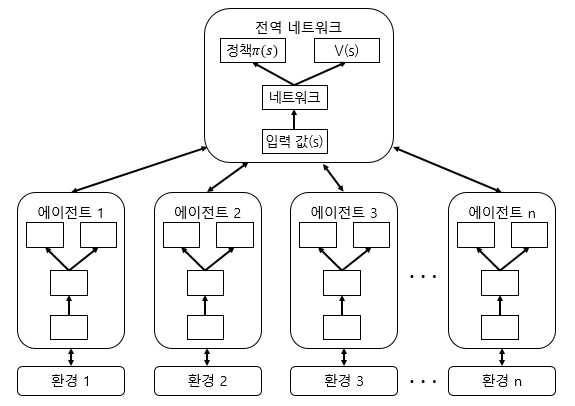
동일한 신경망 모델로 되어 있는 각 actor-learner는 서로 다른 환경에서 비동기적으로 일정 시간동안 행동하면서 샘플을 생성한다. 이렇게 여러 actor-learner가 생성한 샘플들을 이용하여 신경망 모델을 학습시키고, 학습된 신경망 모델을 다시 actor-learner에 복사하는 방식이다.
위 과정을 반복함으로써 리플레이 메모리를 사용하는 효과를 나타낼 수 있다.
Advantage: A = Q(s, a) - V(s)
Advantage(A): 어떤 에이전트의 액션이 예상보다 얼마나 더 좋은 결과를 냈는지를 결정
V(s): 네트워크의 가치함수로 어떤 상태가 얼마나 좋은지를 나타낸다.
π(s): 일련의 액션의 확률 출력값 (정책)
에이전트의 액션이 얼마나 좋은지를 확인하는 것이 아닌 예상보다 얼마나 더 좋은 결과를 냈는지를 결정할 수 있어야 한다. 그러므로, A3C에서는 할인된 보상이 아닌 advantage 추정값을 사용해야한다. 이렇게 사용하면 알고리즘에서 네트워크의 예측이 부족한 부분에 집중 가능하다.
A3C에서는 Q값을 직접 결정하지 않으므로 할인된 보상 R = γ(r)을 Q(s, a)의 추정값으로 이용하여 advantage의 추정값을 구할 수 있다: A = R - V(s)
학습 과정
1. 에이전트가 전역 네트워크로 리셋된다.
2. 에이전트가 환경과 상호작용한다.
3. 에이전트가 가치와 정책 비용을 계산한다.
4. 에이전트가 비용으로부터 경사를 구한다.
5. 에이전트가 경사를 이용해 전역 네트워크를 업데이트한다.
위 과정을 계속해서 반복한다.
'AI > 강화학습' 카테고리의 다른 글
| [강화학습] 2. 멀티암드 밴딧 문제(muti-armed bandit) (0) | 2021.01.28 |
|---|---|
| [강화학습] 1. 강화학습의 기본 개념들 (0) | 2021.01.27 |

